Sometimes, we require to find duplicate records in database, especially when the client asks you to remove the duplicate records. But we can’t check thousands of records manually one by one and then remove it. Instead of we can easily create a simple query to find out the duplicate records. Let’s just see it.
| Table of Contents |
| 1. Check Duplicate Records Exists In Database |
| 2. Fetch All Duplicates Records In Database |
01 Check Duplicate Records Exists In Database
We have prepared the following query to find out duplicate records. To make the following query work, you just need to change the column_name to yours, in which you want to find the duplicate records and also don’t forget to change the table_name to your database table name.
Syntax:
SELECT
`column_name`, COUNT(column_name) AS NumOccurrences
FROM `table_name`
GROUP BY `column_name`
HAVING (COUNT(column_name) > 1)
The GROUP BY clause groups the rows into groups by values of provided columns.
The COUNT() function returns the number of occurrences of the group.
HAVING is important here because HAVING is used filters on aggregate functions.
Example:
Here, we are going to give you an example of the MySQL database server. This query might be the same for all the database servers or change according to your database server.
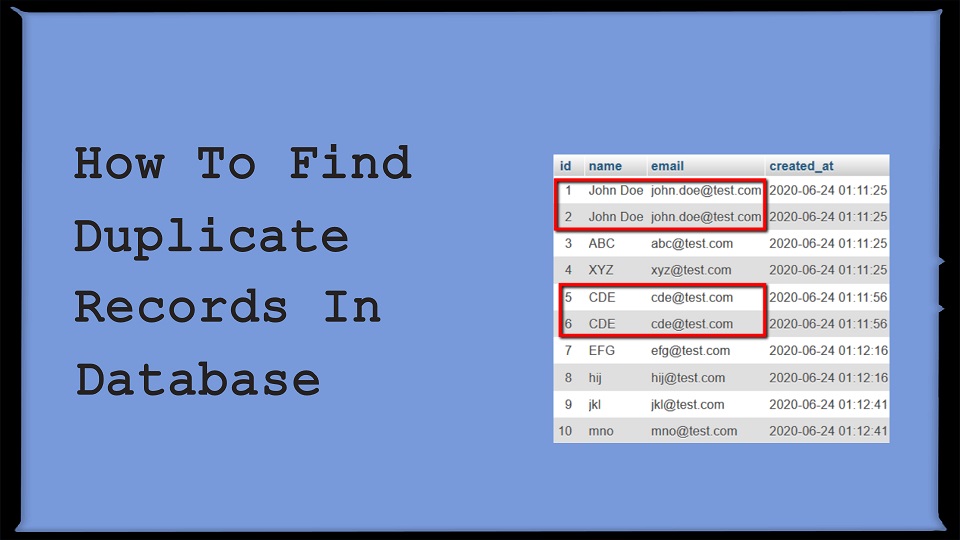
Table Name: Users
You can see in the following screenshot, we have 2 duplicate records in terms of email. So let’s find out the duplicate records using simple query using email column.

Query:
SELECT
`email`, COUNT(email) AS NumOccurrences
FROM `users`
GROUP BY `email`
HAVING (COUNT(email) > 1)
Output:
email | NumOccurrences
----------------------------------
cde@test.com | 2
john.doe@test.com | 202 Fetch All Duplicates Records In Database
In the previous step, we have seen that our query returned a list of duplicates records. But now, we will try to fetch the entire record for each duplicate row.
To do this, we need to select the whole table and then need to join that with our duplicate records as below:
SELECT a.*
FROM users AS a
JOIN (SELECT *, COUNT(*)
FROM users
GROUP BY email
HAVING count(*) > 1 ) AS b
ON a.email = b.email
ORDER BY a.email
In that above example, we have inner join duplicated data as per our first query with all the columns of users table. Because we’re joining the table to itself, it’s necessary to use aliases (here, we have used a and b) to label the two versions.
Here is what our results look like for this query:
id | name | email | created_at
-------------------------------------------------------
5 | CDE | cde@test.com | 2020-06-24 01:11:56
6 | CDE | cde@test.com | 2020-06-24 01:11:56
1 | John Doe | john.doe@test.com | 2020-06-24 01:11:25
2 | John Doe | john.doe@test.com | 2020-06-24 01:11:25That’s it for now. We hope this article helped you find duplicate records in database.
Additionally, read our guide:
- How to Select Data Between Two Dates in MySQL
- Error After php artisan config:cache In Laravel
- Specified Key Was Too Long Error In Laravel
- AJAX PHP Post Request With Example
- How To Use The Laravel Soft Delete
- How To Add Laravel Next Prev Pagination
- cURL error 60: SSL certificate problem: unable to get local issuer certificate
- Difference Between Factory And Seeders In Laravel
- Laravel: Increase Quantity If Product Already Exists In Cart
- How To Calculate Age From Birthdate
- How to Convert Base64 to Image in PHP
- Check If A String Contains A Specific Word In PHP
- PHP: Get First Element Of Array With Examples
Please let us know in the comments if everything worked as expected, your issues, or any questions. If you think this article saved your time & money, please do comment, share, like & subscribe. Thank you in advance 🙂. Keep Smiling! Happy Coding!

